Linux内核网络收包流程
文章目录
初始化
设备有很多种方法来告知计算机系统的其他部分某个工作已经准备好进行下一个过程的处理。对于网络设备来说,网卡通常会发起一个IRQ中断来通知一个网路包的到达并且这个网络包已经准备好接收下一阶段的处理。在Linux内核中执行的IRQ handler具有很高的优先级,并且在其执行期间(中断上下文中)通常会阻塞后续到来的新IRQ。因此,设备驱动所注册的IRQ handler必须要尽可能快地执行并且将那些可能会执行很长时间的过程推迟到当前这个中断上下文之外执行。Linux内核提供了软IRQ,tasklet和workqueue三种方式来执行这种后台任务。就网络设备而言,软IRQ系统用于处理网络包的接收与处理。软IRQ系统在内核启动的早期被初始化。
软IRQ系统的初始化过程大致如下:
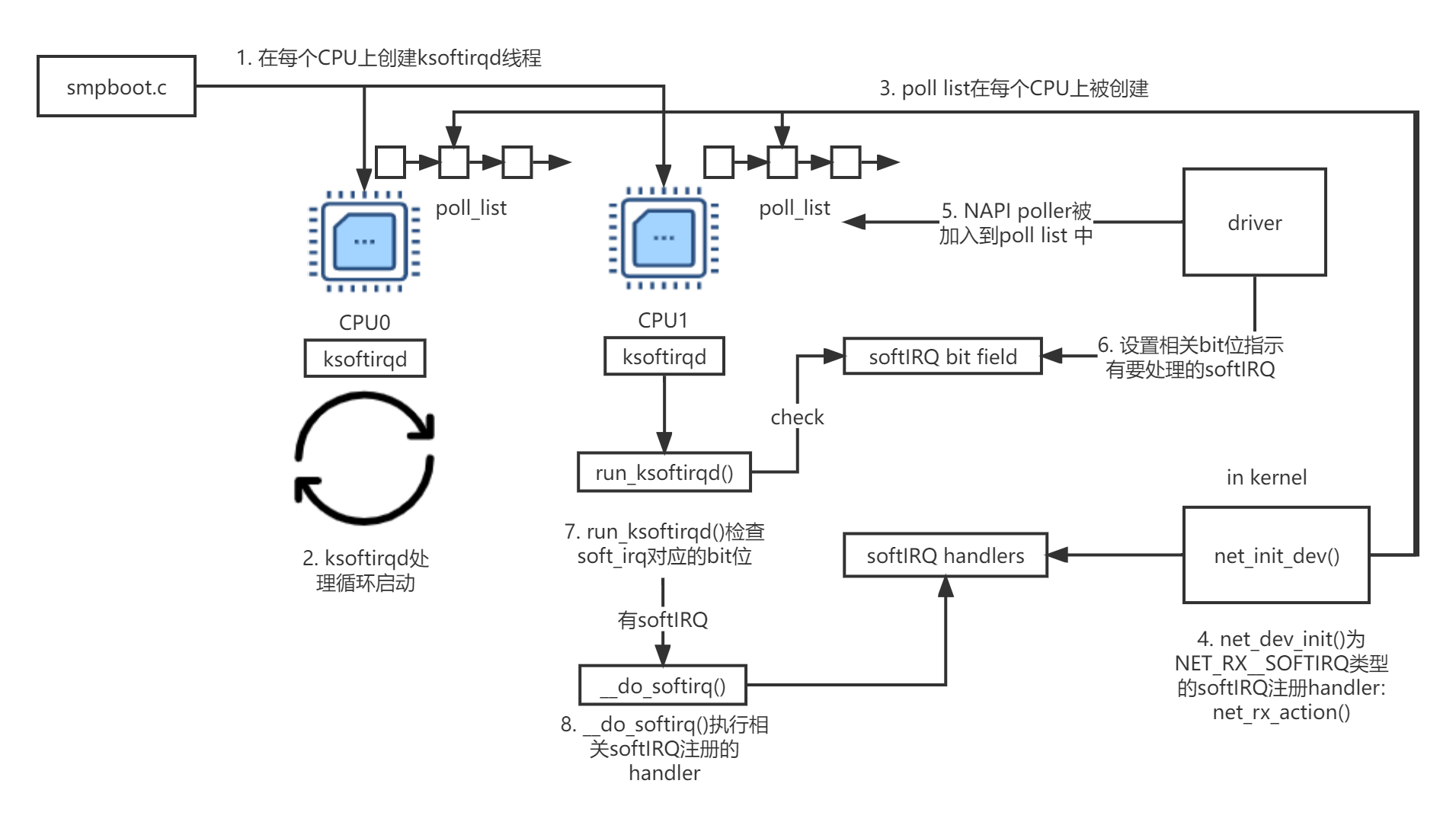
- 用于处理软IRQ的内核线程在CPU的每个核上通过
kernel/smpboot.c:smpboot_register_percpu_thread中对kernel/softirq:spawn_ksoftirqd()的调用被初始化。可以看到.thread_fn被赋值为run_ksoftirqd,它将会在一个循环中被调用。
|
|
-
ksoftirqd线程在
run_ksoftirqd函数上开始无限循环。 -
接着,
struct softnet_data的实例在每个CPU核上被创建,他们用来保存用于处理网络包的重要数据结构的引用,例如poll_list。设备驱动将会通过napi_schedule()或其他NAPI的API将NAPI worker结构添加到poll_list当中。 -
随后,
ner_dev_init()通过open_softirq()注册NET_RX_SOFTIRQ类型的软IRQ。其中回调函数被注册为net_rx_action(),softirq内核线程将通过这个函数处理接收到的网络包。
|
|
网络数据到来
主要流程
当网络上的数据到达网卡后,网卡会通过DMA将网络包写入到内存中,同时ring buffer中保存指向这些数据包的指针。值得注意的是,有些网卡是对队列网卡,他们会将到来的网络数据包写入到多个ring buffer中的其中一个。下面以只有一个ring buffer的网卡为例说明接收数据的过程。
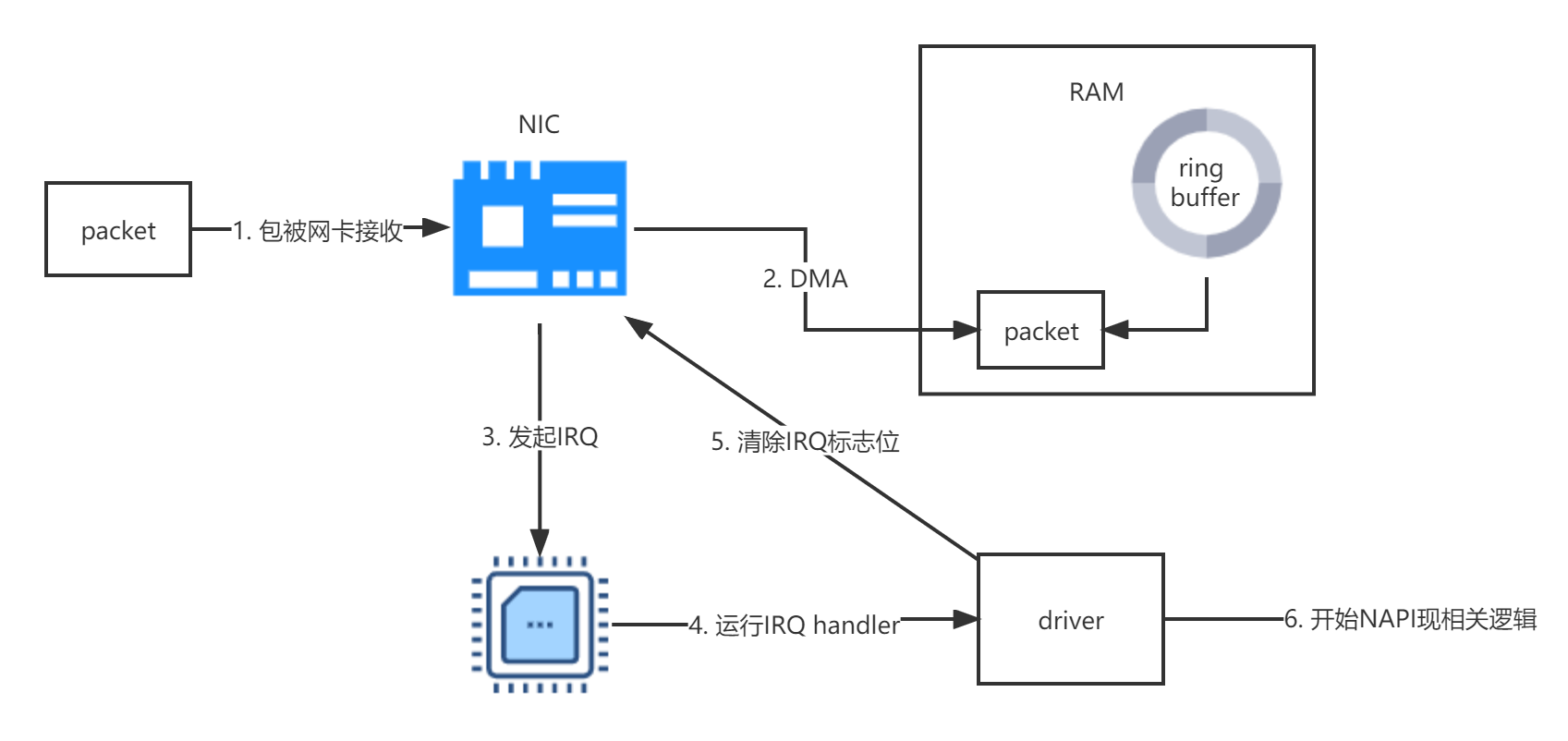
-
数据从网络到达网卡。
-
网卡通过DMA将数据包写入到内存中。
-
网卡发起一个IRQ。
-
网卡驱动注册的对应IRQ handler被执行。
-
网卡上的IRQ被清除,之后可以对新来的包发起新的IRQ。
-
对
napi_shcdule()的调用启动NAPI softIRQ poll loop。
在napi_schedule()中,通过设置一个bit并且将一个结构添加进poll_list中来开启NAPI softIRQ poll loop。就是在这里设备将处理过程推迟到softIRQ。
-
对
napi_shcdule()的调用将设备的NAPI poll结构添加到当前CPU的poll_list当中。 -
softIRQ的pending bit被设置使得当前CPU上的
ksoftirqd线程知道有新的softIRQ需要处理。
|
|
run_ksoftirqd()函数被执行。
|
|
- 当检查有未决的softIRQ时,执行
__do_softirq(),在其中执行被注册的回调函数net_rx_action(),这个函数将会进行对网络包的处理。
|
|
网络数据包的处理
主要流程
现在,网络数据包将会被处理。在内核线程ksoftirqd上执行的net_rx_action()函数将会处理所有在被加入到当前CPU的poll_list中的NAPI poll结构。在两种情况下poll structure会被加入到poll_list中:
- 设备驱动调用了
napi_schedule()。 - 在RPS开启的情况下,其他核通过IPI通知。
接下来我们将解析设备的NAPI poll structure被从poll_list中取出后发生了什么。
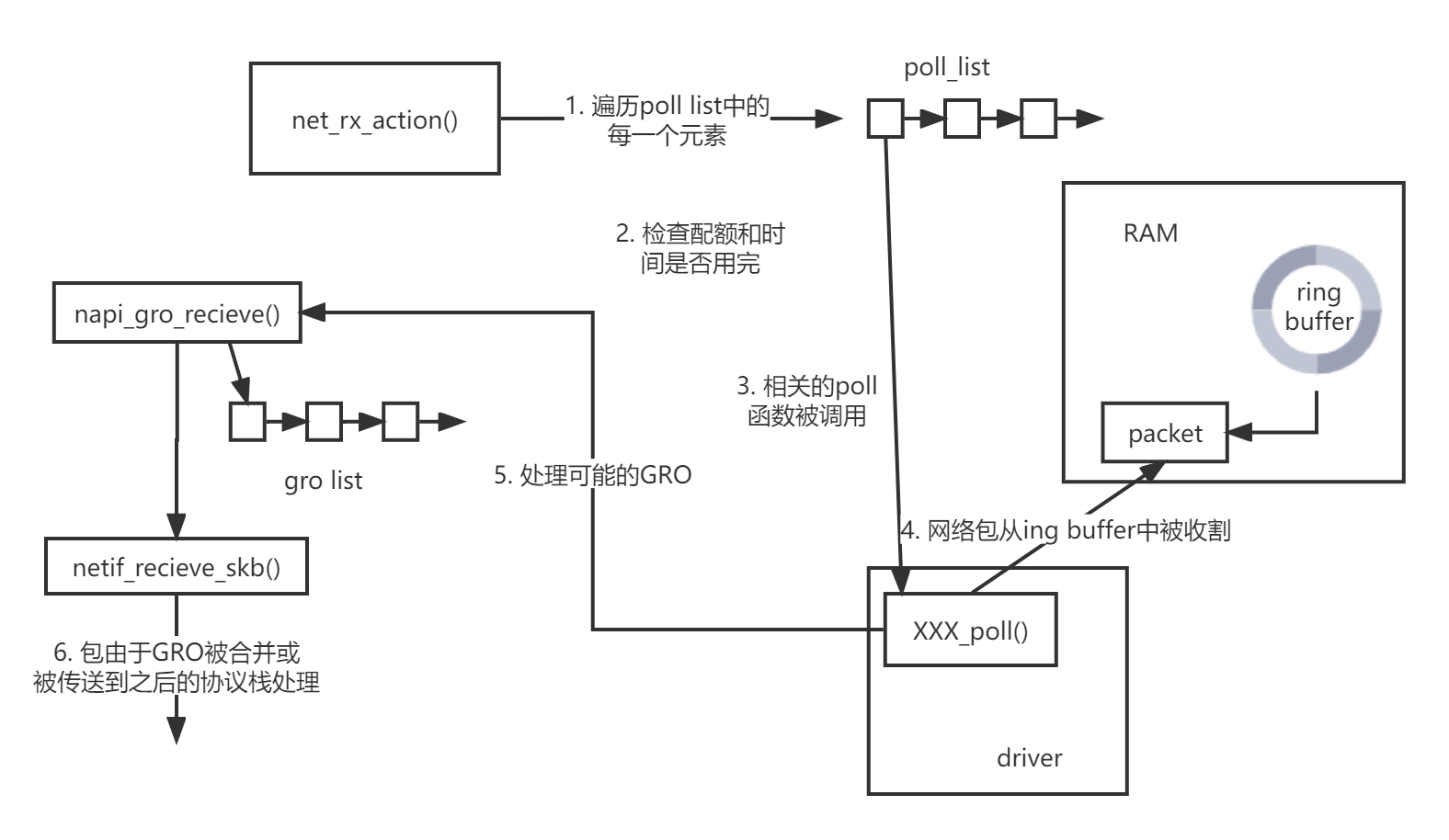
-
net_rx_action()中循环遍历检查poll中的每一个NAPI structures。 -
检查配额和经过的时间以保证对当前softIRQ的处理没有占用当前CPU太长时间。
-
被注册的poll回调函数被调用,它将收割ring buffer中的网络数据。
-
数据包继续通过
napi_gro_recieve()->dev_gro_receive()用于处理可能的GRO优化。 -
在经过GRO处理后,数据包的处理要么结束(通过
napi_skb_finish来释放因合并而不需要的数据包),要么继续通过netif_receive_skb()处理,形成struct sk_buff,正式成为Linux内核中能够处理的网络包结构并继续向上进行内核协议栈,netfilter, BPF等的进一步处理。
|
|
GRO
GRO (Generic Receive Offloading)功能是对分片的包进行重组然后交给更上层,以提高吞吐。 GRO 给协议栈提供了一次将包交给网络协议栈之前,对其检查校验和 、修改协议头和发送应答包的机会。
- 如果 GRO 的 buffer 相比于包太小了,它可能会选择什么都不做;
- 如果当前包属于某个更大包的一个分片,调用
enqueue_backlog()将这个分片放到某个 CPU 的包队列;当包重组完成后,会交会协议栈网上送; - 如果当前包不是分片包,传递给上层。
GRO 的主要思想都是通过合并类似的包来减少传送给网络栈的包数从而减少 CPU 的使用量。但是其可能会导致信息丢失。
接下来netif_receive_skb()将会根据RPS功能是否开启来执行不同的动作。
当RPS关闭时:
netif_receive_skb()将数据传递给__netif_receive_core(),它将完成把数据包送入内核协议栈之前的所有繁重工作,这包括:- 处理 skb 时间戳;
- Generic XDP:软件执行 XDP 程序(XDP 是硬件功能,本来应该由硬件网卡来执行);
- 处理 VLAN header;
- TAP 处理:例如 tcpdump 抓包、流量过滤;
- TC:TC 规则或 TC BPF 程序;
- Netfilter:处理 iptables 规则等。
TUN/TAP模块为用户空间提供了一种虚拟网卡,使得网络数据包可以直接从用户空间进程发送到内核当中,其可以工作在L2或L3。
__netif_receive_core()将数据传递给注册的协议栈回调函数,通常是IPv4注册的ip_rcv()。
RPS功能开启时:
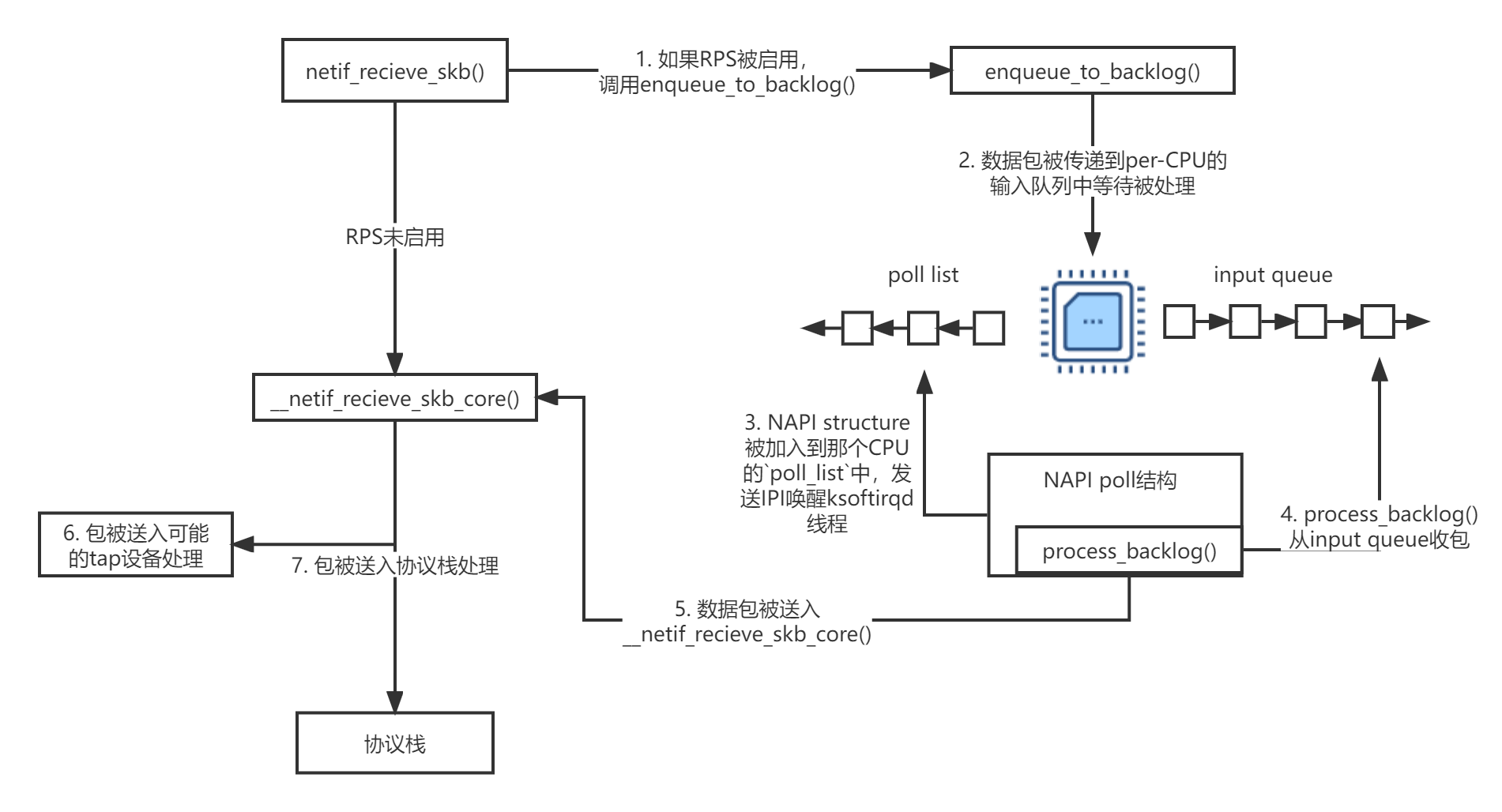
netif_receive_skb()将数据传递给enqueue_to_backlog()。- 数据包被传递到per-CPU的输入队列中等待被处理。
- 目标CPU的NAPI structure被加入到那个CPU的
poll_list中,之后将通过一个IPI触发目标CPU上的ksoftirqd内核线程唤醒如果它当前没有在运行。 - 当目标CPU上的
ksoftirqd内核线程运行后,它将遵从和上面之前一样的过程进行处理。只不过这一次被注册的poll函数process_backlog()将收割当前CPU输入队列中的网络包。 - 数据被传递给
__netif_receive_core(),之后的过程同上。
|
|
RSS, RPS, RFS
RSS(Receive Side Scaling) :每个 NAPI 变量都会运行在相应 CPU 的软中断的上下文中。而且,触发硬中断的这个 CPU 接下来会负责执行相应的软中断处理函数来收包。换言之,同一个 CPU 既处理硬中断,又 处理相应的软中断。
另一方面,DMA 区域是网卡与内核协商之后预留的内存,由于这块内存区域是有限的, 如果收到的包非常多,单个 CPU 来不及取走这些包,新来的包就会被丢弃。 一些网卡有能力将接收到的包写到多个不同的内存区域,每个区域都是独立的接收队列,即多队列功能。 这样操作系统就可以利用多个 CPU(硬件层面)并行处理收到的包。
如今大部分网卡都在硬件层支持多队列。这意味着收进来的包会被通过 DMA 放到 位于不同内存的队列上,而不同的队列有相应的 NAPI 变量管理软中断 poll()过程。因此, 多个 CPU 同时处理从网卡来的中断,处理收包过程。
RPS(Receive Packet Steering)是 RSS 的一种软件实现。因为是软件实现的,意味着任何网卡都可以使用这个功能,即便是那些只有一个接收队列的网卡。但也正是因为是软件实现的,意味着 只有在 packet 通过 DMA 进入内存后,RPS 才能开始工作。这意味着,RPS 并不会减少 CPU 处理硬件中断和 NAPI poll()(软中断最重要的一部分)的时间, 但是可以在包到达内存后,将它们分到其他 CPU,从其他 CPU 进入协议栈。
RPS 的工作原理如下:
- 对 packet 做 hash,以此决定分到哪个 CPU 处理;然后 packet 放到每个 CPU 独占的 backlog 队列。
- 从当前 CPU 向对端 CPU 发起一个IPI,如果当时对端 CPU 没有在处理 backlog 队列收包,这个 IPI 会触发它开始从 backlog 收包。
RFS(Receive flow steering)和 RPS 配合使用。RPS 试图在 CPU 之间平衡收包,但是没考虑数据的局部性问题,如何最大化 CPU 缓存的命中率。RFS 将相同 flow 的包送到相同的 CPU 进行处理,可以提高缓存命中率。RFS 可以用硬件加速,网卡和内核协同工作,判断哪个 flow 应该在哪个 CPU 上处理。这需要网 卡和网卡驱动的支持。
网络协议栈和用户空间sockets
接下来数据包将会继续往上经过协议栈,netfilter, BPF的处理最终到达用户空间中的sockets当中。以下为大致流程:
-
数据包被IPv4的
ip_rcv()接收。 -
内核进行Netfilter的相关处理和路由优化。
-
数据包被继续送给更上层的协议栈。
-
以UDP为例,UDP通过
udp_rcv()接收数据并通过udp_queue_rcv()和sock_queue_rcv()将其送入用户态socket中的接收buffer中。在将其送入接收buffer之前,进行BPF的处理。
文章作者 bobh
上次更新 2022-11-20