BPF Performance Tools 笔记
文章目录
技术背景
-
动态插桩:kprobes, uprobes
- 接口可能不稳定
- 编译器的内联优化可能使得无法使用动态插桩
-
静态插桩:tracepoint, USDT
-
kprobes: kprobes可以对任何内核函数或函数内部的指令进行动态插桩。kprobes插桩原理如下:
- 将在要插桩的目标地址的字节内容复制并保存
- 以单步中断指令覆盖目标地址(在x86上式int3指令,若开启优化为jmp指令)
- 当指令执行到断点时,断点处理函数会检查这个断点是否是由kprobes注册的,若果是,则执行kprobes处理函数
- 当不再需要kprobes时,原始的字节内容会被复制回目标地址上,这样这些指令就回到了初始装状态
有三种接口访问kprobes:
- kprobe API: 写一个内核模块,通过
register_kprobe()注册,加载内核模块输出内容,然后取消注册。 - 基于Ftrace,通过向
/sys/kernel/debug/tracing/kprobes_events写入字符串进行控制 perf_event_open()
-
uprobes: uprobes提供了用户态程序的插桩,原理接口等和kprobes类似
-
跟踪点: 内核开发者在内核函数中的特定逻辑处防止了一个插桩点,这些跟踪点会被编译到内核二进制文件中。
-
USDT: 用户定义静态跟踪提供了用户空间的跟踪机制
性能分析
调用栈回溯
- 基于帧指针的调用栈回溯:按照惯例,函数调用栈帧链表的头部地址始终保存于某个寄存器中(x86_64中为rbp),于是可以通过读取rbp后遍遍历调用栈。AMD64 ABI提到,rbp作为帧指针寄存器为惯例而不是轻质要求。为了节省函数prolugue和epilogue指令数量,可以将rbp作为通用寄存器使用。
gcc默认不启用函数帧指针,可通过-fno-omit-frame-pointer选项来强制开启。 - 调试信息:额外调试信息以debufinfo packages提供,其中包括了DWARF格式的ELF调试信息,相关文件段为
.eh_frame和debug_info。 - 最后分支记录(LBR):Intel处理器有意向特性,程序分支包括函数调用分支信息被记录在硬件缓冲区中。该记录没有额外开销但支持的深度有限。
- ORC:一种新的调试格式。
Linux 60s分析
uptime: 检查平均负载,确保性能问题仍然存在dmesg | tail: 通过系统日志查找可能的错误vmstat 1: 统计虚拟内存的情况(参数1表示每1秒输出一次,下同)。需检查:r: CPU上正在执行和等待的进程数量,相比平均负载来说,它不包含I/Ofree: 空闲内存大小si/so: 页换入和换出us: 用户态时间,sy: 内核态时间,id: 空闲I/O,wa: 等待I/O,st: 被窃取时间 (均为所有CPU的平均值)
mpstat -P ALL 1: 详细列出每个CPU的统计指标pidstat 1: 按照每个进程展示CPU的使用情况,其中%CPU是对所有CPU相加的和iostat -xz 1: 显示存储设备I/O指标,检查指标:r/s,w/s,rkB/s,wkB/s: 每秒向设备发出的读写次数和读写字节数,描述了业务负载await: I/O的平均相应时间avgqu-sz: 设备请求队列的平均长度%util: 设备使用率
free -m: 以MB为单位检查内存情况sar -n TCP,ETCP 1: 使用sar查看TCP指标和TCP错误信息。检查指标:active/s: 每秒本地发起的TCP连接数量passive/s: 每秒远端发起的TCP连接数量retrans/s: 每秒TCP重传的数量
BCC工具
execsnoop: 追踪exec(2)系统调用,为每个新创建的进程打印一条信息。可以监测到传统周期执行监控工具发现不了的存活周期短的进程opensnoop: 追踪open(2)(及其变体)系统调用ext4slower: 追踪ext4文件系统常见操作,并可以把超过某个阈值的操作打印出来biolatency: 追踪磁盘I/O延迟(从向设备发出请求到请求完成的时间),以直方图显示biosnoop: 打印每一次磁盘I/O请求cachestat: 打印文件系统缓存信息,每秒打印一次tcpconnect/tcpaccept: 每次主动/被动建立TCP连接时打印信息tcpretrans: 每次TCP重传时打印信息runqlat: 统计线程等待CPU运行的时间,以直方图显示profile: 周期性对调用栈采样,将消重后的调用栈连同出现次数一同打印
BCC
简介
BCC(BPF Compiler Collection)是最早用于开发BPF跟踪程序的高级框架,它提供了一个编写内核BPF程序的C语言环境,同时还提供了其他高级语言的接口。它是libbpf和libbcc的前身,这两个库使用BPF程序对事件进行观测。
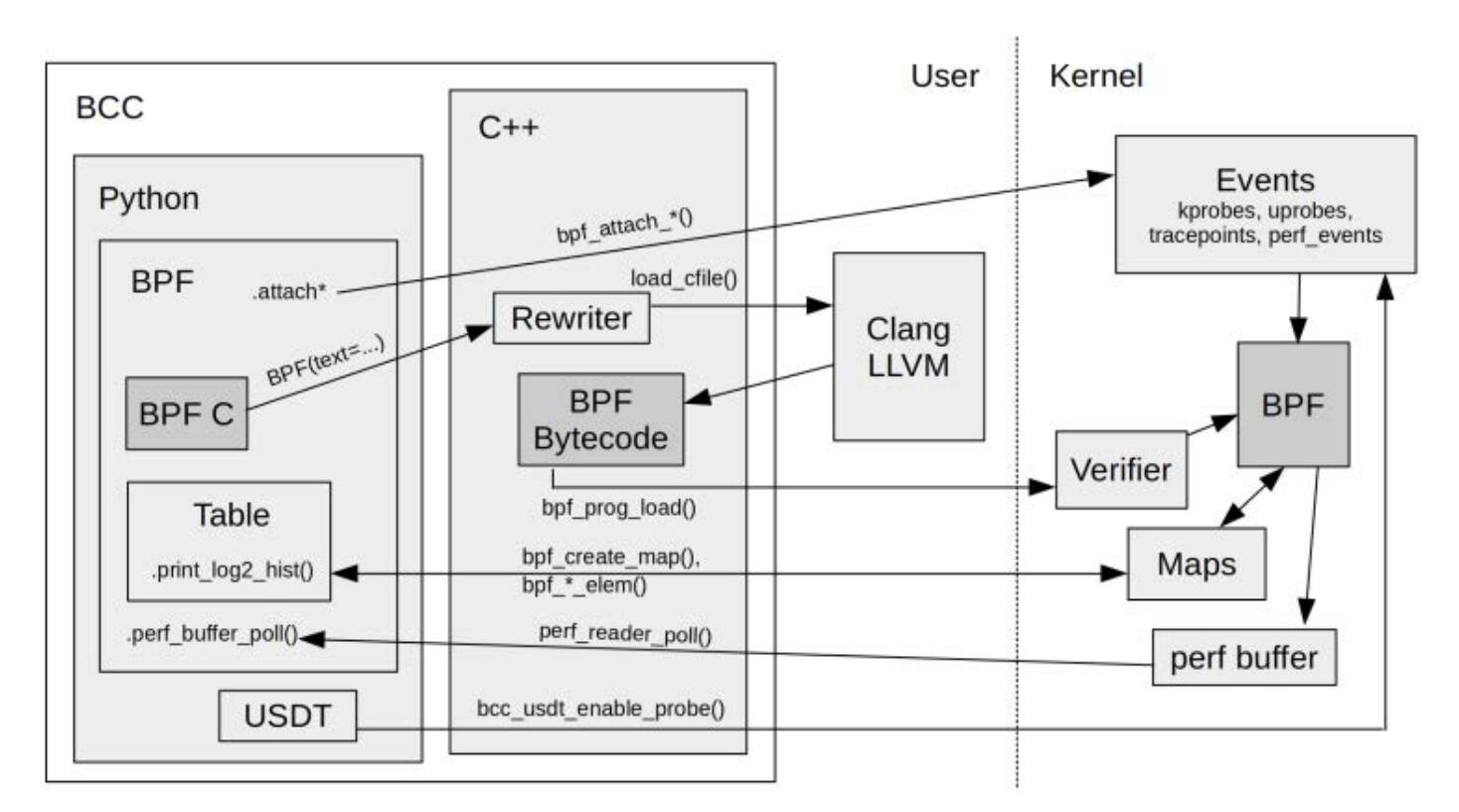
内核要求: 推荐使用Linux 4.9以上的内核版本,需开启以下内核配置选项CONFIG_BPF=y, CONFIG_BPF_SYSCALL=y, CONFIG_BPF_EVENTS=y, CONFIG_BPF_JIT=y, CONFIG_EBPF_JIT=y。
funccount
funccount(8)对事件(函数调用)进行计数
|
|
envname语法如下:
- name/p:name 对内核函数name()插桩
- lib:name/p:lib:name 对用户态lib中函数name()进行插桩
- path:name 对path路径下文件中的函数name()插桩
- t:system:name 对system:name内核跟踪点插桩
- u:lib:name 对lib库中名为name的USDT探针插桩 例子
|
|
stackcount
stackcount(8)对某事件的函数调用栈计数
trace
trace(8)是一个多用途工具,用于跟踪事件源,它会对每个事件产生一行输出,因此不适合高频事件。
|
|
probe语法如下:
|
|
eventname和funccount(8)中的类似,并添加了对返回值的支持
例子
|
|
argdist
argdist(8)用于分析函数调用参数
|
|
-C: 频率统计;-H: 以2的幂次输出直方图 probe语法:
|
|
type为被展示值的类型,expr为要汇总的统计表达式,$retval为返回值,$latency为从进入到返回的时长(ms),$entry(param)为在探针进入时param的值,label用于添加标签文本。例子:
|
|
bpftrace
简介
bpftrace是另一个前端,它提供了一个高级编程语言环境,可以用来轻松地创建Linux追踪程序。bpftrace使用libbpf和libbcc完成对函数的插桩、程序的加载以及使用USDT。它使用LLVM将程序编译成BPF字节码。
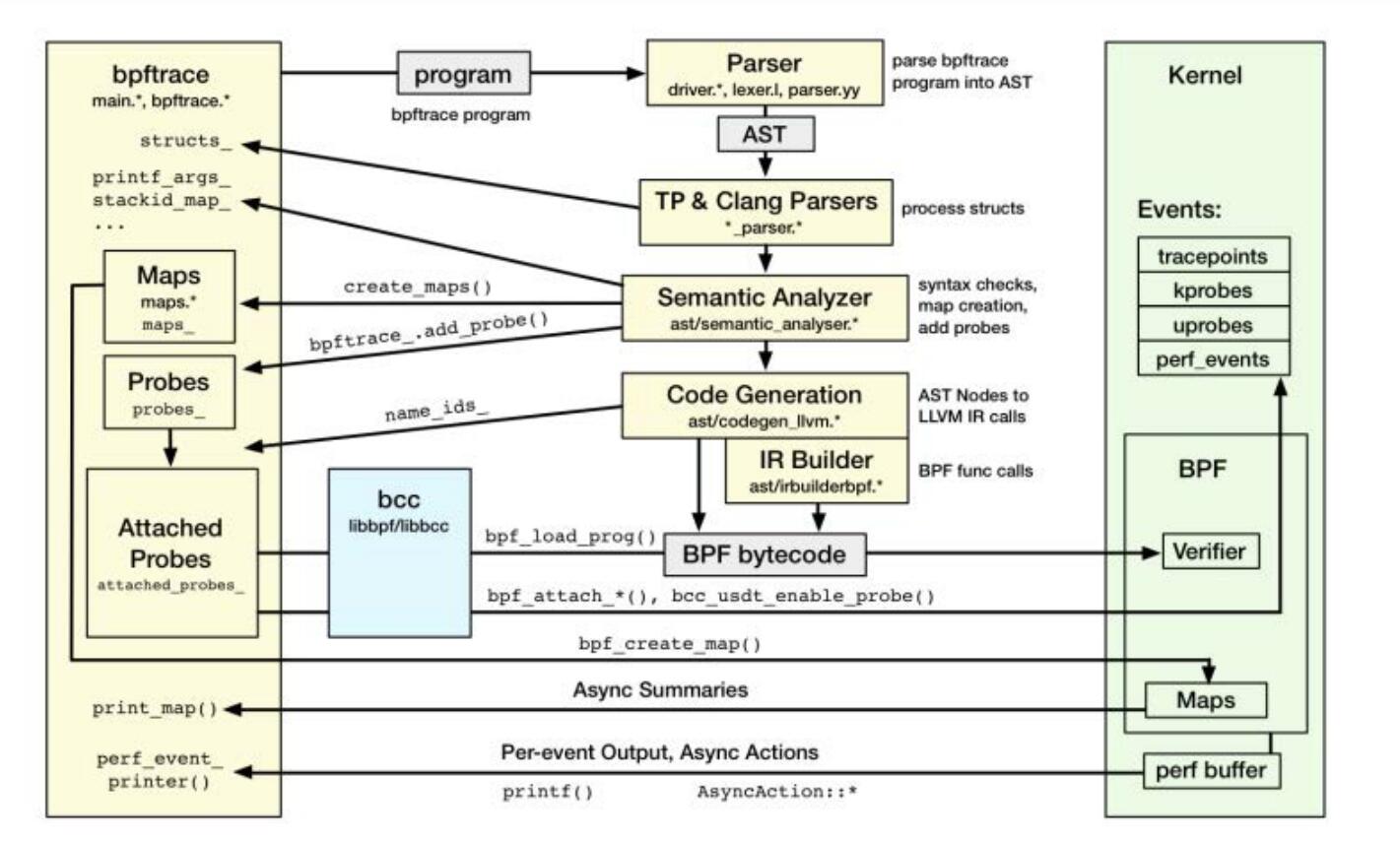
注意部分脚本在官方仓库中没有,可以从这里下载 bpftoolkit
内核要求: 推荐使用Linux 4.9以上的内核版本,需开启以下内核配置选项CONFIG_BPF=y, CONFIG_BPF_SYSCALL=y, CONFIG_BPF_EVENTS=y, CONFIG_BPF_JIT=y, CONFIG_EBPF_JIT=y。
文档: reference_guide
bpf编程
执行程序
|
|
bpftrace程序由一系列探针表对应动作组成
|
|
探针格式
|
|
|
|
探针类型
- tracepoint: 对内核静态跟踪点进行插桩, tracepoint_name包括以冒号隔开的类型和事件名
|
|
|
|
- usdt: 对用户静态探针插桩。可用
bpftrace -l列出可用探针
|
|
|
|
- kprobe/kretprobe: 内核动态插桩
|
|
- uprobe/uretprobe:用户态动态插桩
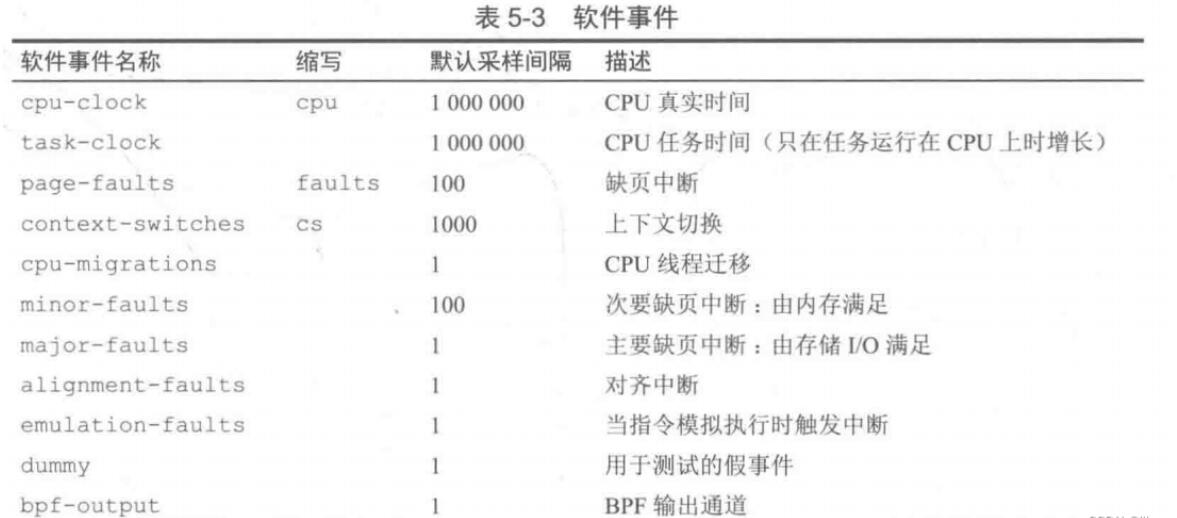
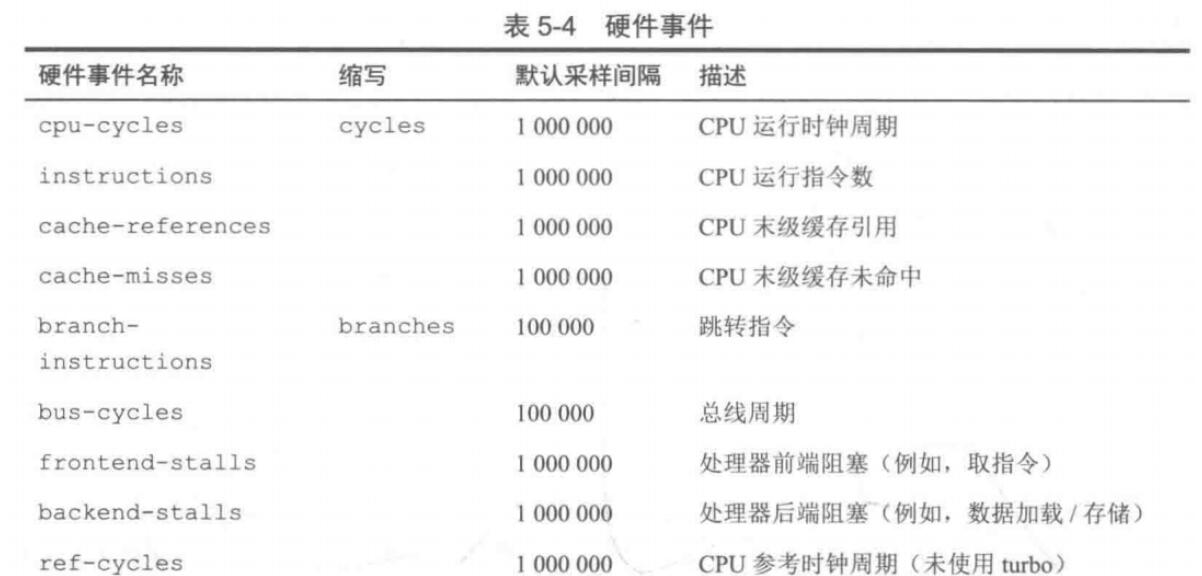
- software/handware: 软件事件和硬件事件,由于发生评论可能很高,使用count表示每发生count次事件才触发一次探针。
- 软件事件:
- 硬件事件:
- 软件事件:
|
|
- profile/inerval: 基于定时器的事件
|
|
变量
有三种类型的变量
- 内置变量,一般作为只读信息源
如pid, tid, cpu(CPU ID), comm(进程名字), nsecs, curtask(当前进程task_struct结构体地址), kstack/ustack(内核/用户态调用栈信息,以多行字符串展现), func(被跟踪函数的名字), $1, ... $N(命令行传递给bpf程序的参数)
- 临时变量,以
$为前缀 - 映射表变量,以
@为前缀,使用BPF映射表来存储对象,可作为全局存储传递数据
|
|
函数
- 通用函数:
printf,time(char *fmt),join(char *strs)(打印字符串),kstack(int limit)/ustack(int limit)(返回一个深度最大为limit的调用栈),ksym(void *p)/usym(void *p)(以字符串形式返回地址处的符号),kaddr(char *name)/uaddr(char *name)(将符号翻译为地址),system(char *fmt, [...])(执shell命令),reg(char *name)(获取指定寄存器的值) - 映射表操作函数:
count(),sum()/min()/max()/avg(),stats()(返回时间次数、平均值和总和),hist()(打印2的幂次直方图),lhist()(打印线性直方图),delete(@m[key])(删除映射表中键值对),clear(@m)(清空映射表)
控制流
- 过滤器
- 三目运算符
- if-else语句
循环
|
|
count最大为20且不能为变量
CPU/内核
分析策略
- 确保待分析对象处于运行状态,检查系统整体CPU利用率(
mapstat(1)),检查是否有CPU处于下限状态 - 确认系统负载受限于CPU
- 所有CPU负载高还是某个CPU负载高
- 检查运行队列的延迟(
BCC runqlat(1))
- 先量化整个系统的CPU使用量百分比,然后按进程、CPU模式、CPU ID来分解
- 如果系统时间占比高,可按照进程和系统调用类型来统计系统调用的频率和数量,同时检查系统参数来识别可以优化的地方(
perf(1),BCC syssstat(8), bpftrace单行程序)
- 如果系统时间占比高,可按照进程和系统调用类型来统计系统调用的频率和数量,同时检查系统参数来识别可以优化的地方(
- 使用profiler采样调用栈信息,用火焰图展示
- 针对某个任务定制工具获取相关上下文信息
- 测量硬中断的资源消耗,这些信息对于基于定时器的分析器不可见(如
BCC hardirqs(1)) - 利用PMC来观测每周期CPU指令执行量,利用
BCC llcstat分析缓存低命中率等
传统工具
upitme, top, mpstat, perf, Ftrace
BPF工具
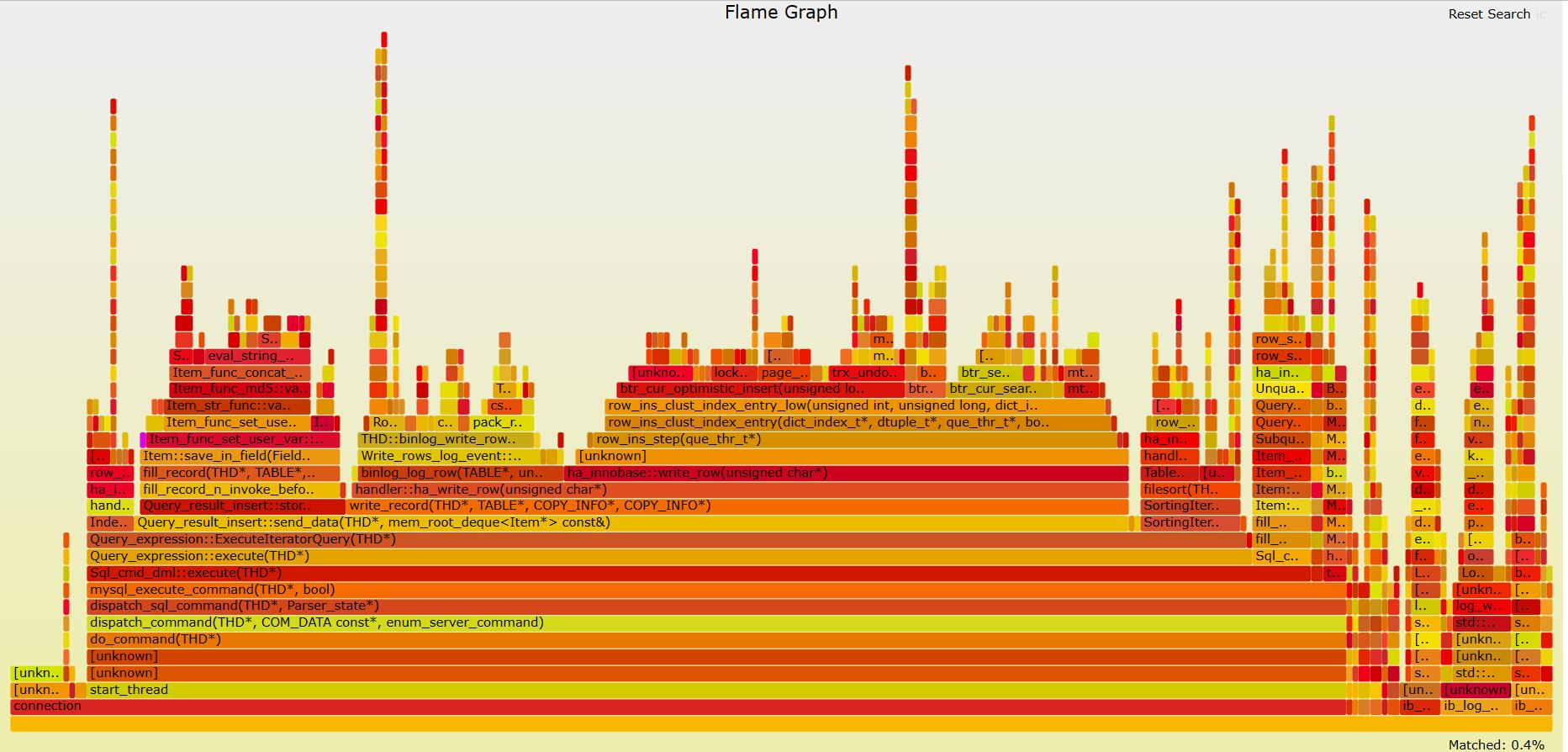
profile
profile(8)定时采样调用栈信息并汇报调用栈出现频率。其频率统计在内核态完成。而其他内核态分析工具如perf(1)将采样信息发送到内核态后进行处理才得出统计信息。profile(8)避免了采样过程中对文件系统和磁盘I/O的消耗,更加高效。
常用选项:-f: 以折叠方式输出, , -F FREQUENCY: 指定采样频率, -p PID: 仅输出给定进程, -u: 仅包含用户态线程, -k: 仅包含内核态线程, -U: 仅包含用户态调用栈信息, -K: 仅包含内核态调用栈信息。
下面是使用执行employees测试表验证脚本的火焰图
|
|
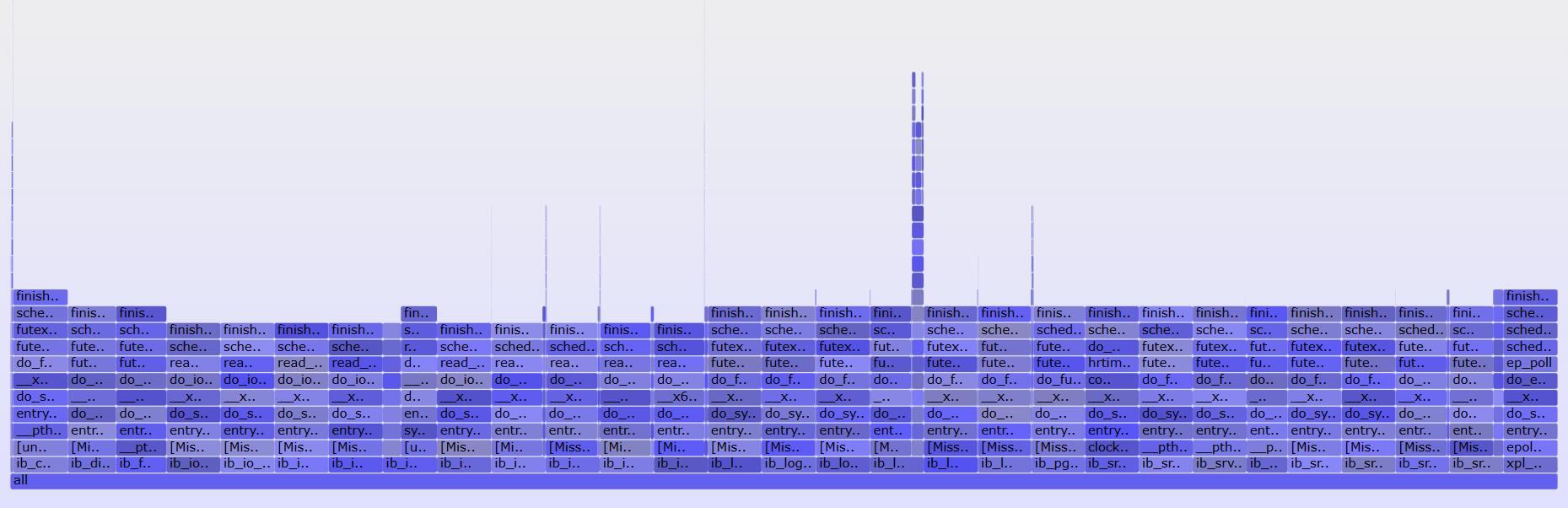
offcputime
offcputime(8)用于统计线程阻塞和脱离CPU运行的时间,同时输出调用信息。其和profile(8)工具结合起来覆盖了线程的全部生命周期。输出格式和profile(8)相同。由于输出信息较多,可打成火焰图进行分析。
offcoutime(8)通过跟踪上下文切换时间完成统计,同时记录调用栈信息。由于上下文切换事件在内核中发生频繁。故其额外消耗较大,更适合短期运行。
常用选项如下:-f: 以折叠方式输出, -p PID: 仅输出给定进程, -u: 仅包含用户态线程, -k: 仅包含内核态线程, -U: 仅包含用户态调用栈信息, -K: 仅包含内核态调用栈信息, --state STATE: 筛选特定状态的线程(如2表示TASK_UNINTERRUPTIBLE)
以下为导入employees测试表过程的offcputime火焰图
|
|
 搜索高亮
搜索高亮
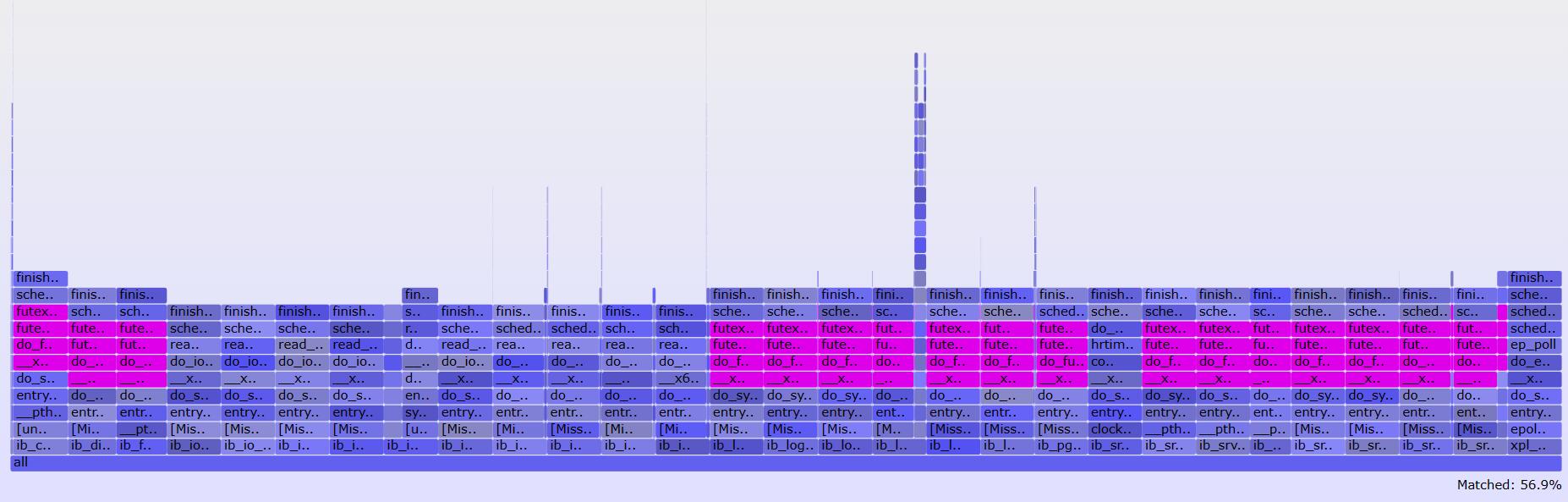
使用折叠文件格式时可以先使用grep(1)过滤出关心的线程再生成火焰图
|
|
mlock/mheld
mlock(8)和mheld(8)以直方图形式跟踪内核互斥锁的延迟和持有时间,并输出内核态堆栈。mlock(8)可用来定位锁争用问题,mheld(8)可以显示那个代码路径长时间尺有锁。由于mutex没有跟踪点,mlock(8)/mheld(8)跟踪了mutex_lock(), mutex_lock_interruptible(), mutex_trylock()内核函数,由于这些函数调用频繁,故开销较大。
|
|
|
|
自旋锁没有跟踪点,可以通过BCC funcount(8)进行跟踪
其他工具
runqlat(8)用于分析CPU调度器延迟,统计每个线程等待CPU的耗时,输出直方图runqlen(8)通过采样CPU运行队列长度,统计有多少个线程在等待执行,输出直方图。-C选项按CPU输出结果runqslower(8)列出运行队列中超过阈值的线程名字cpudist(8)统计每次线程唤醒后在CPU上执行时长,输出直方图wakeuptime(8)可展示执行调度器唤醒线程的调用栈以及目标被阻塞的时间offwaketime(8)结合了offcputime(8)和wakeuptime(8)numamove(8)用于跟踪类型为NUMA misplaced的内存页面迁移。syscount(8)用于统计系统调用的次数argdist(8)可用于读取参数的直方图信息,tplist(8)可查询各个参数的信息
|
|
kmem(8)按调用栈显示内核内存分配的统计信息
内存
BPF工具
memleak(8)展示长时间不被释放的内存mmapsnoop(8)跟踪全系统的mmap(2)系统调用并打印映射的详细信息faults(8)跟踪缺页错误和调用栈信息drsnoop(8)跟踪内存释放过程中的直接回收部分,显示对应的延迟
文件系统
分析策略
- 识别系统中挂载的文件系统(
df(1),mount(8)) - 检查挂载的文件系统的容量,某些文件系统在接近100%容量时会有性能下降的情况
- 产生一个固定的负载进行分析(
fio(1)) - 使用
opensnoop(8)观察打开的文件,使用filelife(8)来查找是否存在短期文件问题 - 查找非常慢的文件系统操作,按进程和文件名详细观察(
ext4slower(8),btrfsslower(8),zfsslower(8)),或使用性能损耗偏高的通用工具(fileslower(8)) - 检查文件系统的延迟分布(
ext4dist(8),btrfsdist(8),zfsdist(8)),这有可能会显示导致性能问题的延迟成双峰分布或离群情况 - 检查一段时间内也缓存的命中率(
cachestat(8)) - 使用
vfsstat(8)来比较逻辑I/O和物理I/O的区别
BPF工具
syscount(8)用于跟踪系统调用,-x只追踪失败的系统调用(返回值<0),-e ERRNO指定错误码,-p指定进程fmapfault(8)跟踪内存映射文件的缺页错误,按进程名和文件名统计filelife(8)是一个BCC和bpftrace工具,用来展示短期文件的声明周期fileslower(8)用于显示延迟超过某个阈值的同步模式的读取和写入操作cachestat(8)展示也缓存命中率信息bufgrow(8)用于查看缓冲区的内部情况,输出哪个进程导致了也缓冲区的增长,以KB为单位readahead(8)用于跟踪文件系统自动预取的情况,以直方图显示
磁盘
BPF工具
biolatency(8)以直方图方式统计块I/O设备的延迟信息,设备延迟指从向设备发出请求到请求完成的时间,包括在操作系统内排队的信息。-F选项按不同的I/O标识输出直方图,-D选项按磁盘输出直方图bitesize(8)按进程统计磁盘I/O请求直方图biosnoop(8)针对每个磁盘I/O打印一条信息。biopattenr(8)可以识别I/O模式(随机/顺序)biostacks(8)可以跟踪完整的I/O延迟(从进入操作系统队列到完成设备I/O请求),同时显示初始化该I/O请求的调用栈信息,并打印延迟直方图
|
|
网络
分析策略
- 对负载定性分析,找出低效之处
- 使用基于计数器的工具理解基本的网络统计信息:网络包速率和吞吐量,对于TCP,查看TCP连接率和TCP重传率(
ss(8),nstat(8),netstat(10),sar(1)) - 通过跟踪新TCP连接的建立和时长来定性分析负载(
tcplife(8))
- 使用基于计数器的工具理解基本的网络统计信息:网络包速率和吞吐量,对于TCP,查看TCP连接率和TCP重传率(
- 检查各个接口的限制
- 检查是否到达了网络接口吞吐量的上限(
sar(1),nicstat(1)中的接口使用率)
- 检查是否到达了网络接口吞吐量的上限(
- 检查不同的延迟源
- 跟踪TCP重传和其他不寻常的TCP事件(
tcpretrans(8),tcpdrop(8),和skb:kfree_skb跟踪点) - 测量DNS延迟(
gethostlatency(8)) - 测量连接延迟、首字节延迟、软件栈各层之间的延迟等。注意网路延迟测试在不同负载情况下可能由于网络中的缓存鹏膨胀问题而有大幅变化(排队过量导致的延迟)。应在有负载的情况下和空闲网络中分别测量延迟进行比较
- 跟踪TCP重传和其他不寻常的TCP事件(
- 使用实验分析方法
- 使用负载生成工具探索主机之间网络吞吐量的上限,同时检查在已知负载的情况下发生的网路事件
- 使用自定义工具
- 使用高频CPU性能分析工具抓取内核调用栈信息,以量化CPU资源在网络协议和驱动程序之间的使用情况
- 使用跟踪点和kprobes来探索网络协议栈的内部情况
可视化/其他工具
- PCP+Grafana
- Cloudflare eBPF Exporter+Prometheus+Grafana:
- kubctl-trace
- Cilium
- Sysdig
文章作者 bobh
上次更新 2023-05-03