CMU15445-2021 DATABASE SYSTEMS 完成小结
文章目录
PROJECT 1-BUFFER POOL
project 1要我们实现一个buffer pool,buffer pool相当于数据库核心引擎和磁盘之间的一个缓存,负责在磁盘和内存之间传送page
PROJECT 2-EXTENDIBLE HASH INDEX
project2要我们实现一个用于快速检索存储数据的哈希索引,其中哈希表采用Extendible hash的策略来实现。
基本概念
Chained hash
首先通过最普通的chained hash来介绍相关概念。在chained hash中,我们维护一个存储数据的bucket的链表,每次要查询或插入一个数据时,首先通过一个hash函数将key映射到一个更小的空间中的一个点,即slot=hash(key)。同时,每个slot都对应一个bucket,这样就可以通过slot找到对应的bucket从而检索或插入数据,
但是,chained hash中slot的数量的固定的,无法根据需要动态修改,并且可能由于hash函数选取不当而发生hot spot现象从而导致索引的效率降低。
extendible hash和linear hash都是为了解决chained hash中上述问题的方案,他们的核心思想都是通过适时改变slot和分裂bucket并移动数据来平衡数据的存储,从而减少hot spot的现象。
Linear hash
linear hash维护一个指向下一个要分裂的bucket的sp指针,每当插入一定数量的tuple(通过某个经验公式算出)或当某个页面overflow时,将sp指针所指向的bucket进行分裂,分裂时采用新的hash函数(通常采用hash后结果的最高k位或最低k位,分裂时增加k)对该页面中的数据重新进行分配,之后移动sp指针。(linear hash table可以参考comp9135的实验)
Extendible hash
extendible hash中slot的个数会动态变化,多个slot可以指向同一个bucket。整张表维护一个gloabl_depth表示需要检查的位数,它决定了slot的大小。同时每个bucket维护一个local_depth,这个信息在后面用于分裂与合并中会用到。当插入一个数据导致发生overflow时,将会分裂bucket并重分配其中的数据,如果bucket的local_depth比global_depth小,那么直接将一个新页面分配到一个(些)已有的slot(之前指向该bucket的一部分slot)上,然后重新分配其中的数据。否则,已有的slot中没有可用的slot可以指向新的page,此时要增加global_depth并slot的数量扩大一倍,并把之前slot的相关数据完整的复制到新的slot中,,然后再执行上面分裂的步骤。相关实现细节在后面进行详述。
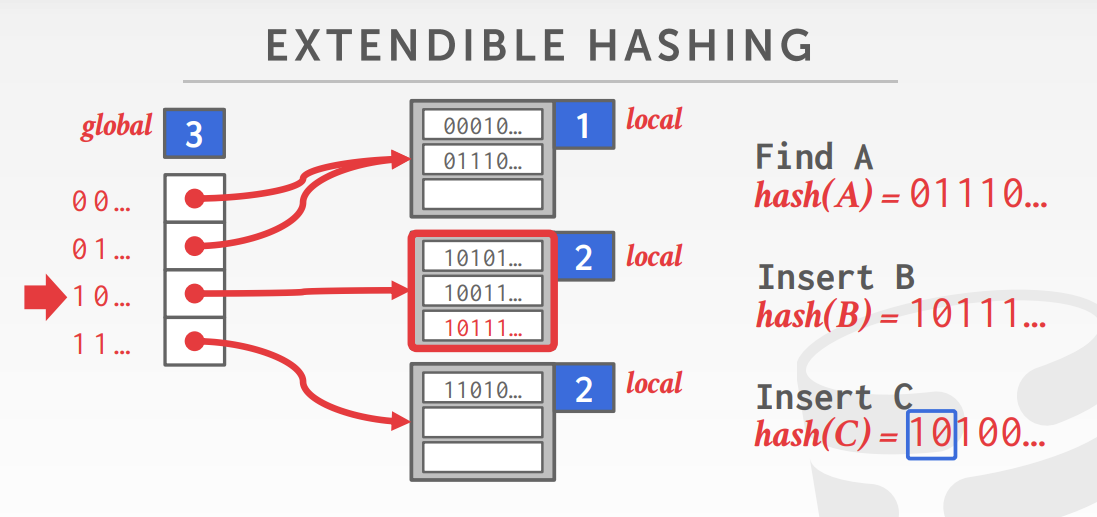
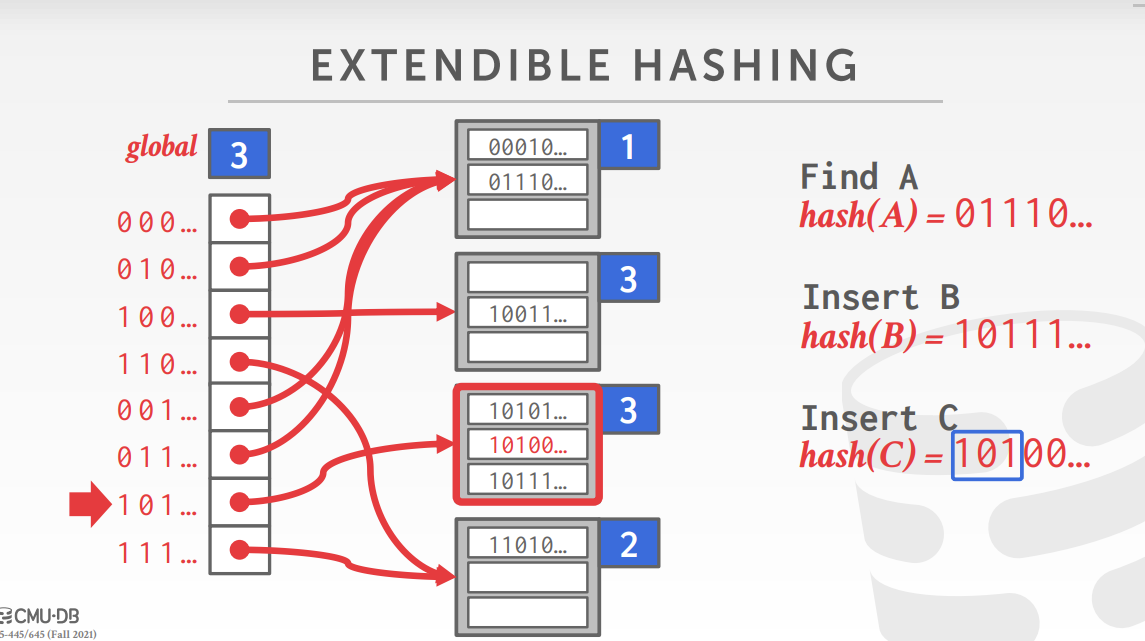
实现
Page layout
在这个projet中,extendible hash table的元数据和实际存储的key-value pair分别在不同的区域存储,每个存储区域均使用page model来进行管理。所以,有两种类型的page,HashTableDirectoryPage和HashTableBucketPage。其中,HashTableDirectoryPage用于存放有关extendible hash table的元数据,HashTableBucketPage用于存放真实的数据。
每次extendiable hash table进行操作时,都要先从buffer pool中请求需要的page(申请资源),读取相应数据并进行修改(使用资源),使用完成后再用UnpinPage()来指示将某个page归还给buffer pool(释放资源)。需要注意NewPage()/FetchPage()和UnpinPage()一定要配对,否则会出现类似与内存管理中dangling pointer,double free,memory leak等问题。
Splite/Merge
bucket的分裂与合并按照其要求实现即可,需要注意的是local_depth这个属性本应该是bucket的属性,但是代码中将相关的元数据都关联到了slot上而不是bucket上(VerifyIntegrity中的代码印证了这一点)。所以在由于Split/Merge需要更新某个bucket的元数据时,需要更新所有指向这个bucket的slot的元数据(包括local_depths_和bucket_page_ids_)。具体来说,当执行IncrGlobalDepth()时,需要将就的slot的元数据复制到新的slot中,然后再进行修改。在Splite一个bucket时,需要将指向原bucket的slot中一般的slot重新指向分离后新的bucket。在进行Merge时,需要将所有指向Merge前的slot重新指向Merge后的bucket。
Concurrency control
下发的代码使用了page latch实现对整个hash table的并发访问。这里的HashTableDirectoryPage和HashTableBucketPage虽然都是存放在buffer pool提供的Page的data字段中的,但由于char data[PAGE_SIZE]是Page的第一个字段,所以我们可以通过reinterprete_cast<Page*>来将一个HashTableDirectoryPage/HashTableBucketPage强转为Page*从而操作Page上的latch。
PROJECT 3-QUERY EXECUTION
实验三要求我们完成基于火山模型的9个query plan对应的查询执行引擎
总体架构
存储与索引
在这个project中,实现索引的数据结构的value中并不存储真实的数据,而是存储一个和真实数据一一对应并能快速找到真实数据的记录(record)。通过这种方式,我们将索引和数据解耦。于是,我们可以将长度相同的数据存储在同一个数据存储空间,同时,当对数据进行修改时,我们不需要在索引数据结构上大量移动数据,而是只需要修改相应的记录即可。具体来说,我们使用在project 2中实现的exendible hash table来实现数据的索引结构。hash table的key对应一个索引,它是某个关系模式上的一个超码(唯一确定关系表中一个元组的属性集),hash table的bucket中的value对应一个RID(Record Identifier),它唯一标识了一个真实数据存储空间的逻辑页号和逻辑序号,通过这个逻辑页号和逻辑序号可以找到一个真实数据(元组),于是一个RID唯一对应了一个存储的元组。
DBMS中关系表的元数据(每张表的关系模式,数据的实际存储位置,表上的索引信息等)被Catalog类所管理,在实现executor的过程中,我们需要通过和Catalog类交互来获取这些元数据。
了解了各个模块的职责后剩下的工作就很简单了,偏底层的API已经需要进行范式转换的地方都已经实现好了,在实现算子的执行引擎时,我们基本上只需要关注它的逻辑,调用相关的API即可。需要注意的是执行引擎完成其功能后再通过Next(...)将产生的结果传递给上层之前一定要将元组转换为其执行计划OutputSchema所规定的关系模式。
project 3在GradeScope上提交时可能出现测试中gtest的一些文件过不了clang-tidy的问题,解决方案是提交的时候把
src/include/storage/page/tmp_tuple_page.h这个文件也提交上去,详见issual#227
CMU15445这门课的几个project从开始写到写完一共花了5条左右的时间,我感觉这个难度还是比MIT6.824要小很多,它给的代码框架基本上已经完成了90%左右,需要我们写的部分很少,并且每个模块的职责和各个模块之间的关系也都很清晰。不同于MIT6.824 lab 4那样需要我们自行设计分片迁移的方案,这个lab中几乎没有需要我们自己设计的内容,每个需要完成的类和函数都有很明确的说明,只要搞懂了各个模块之间的协作关系,就很容易完成。总的来说,这个数据库玩具项目比较简单,但是很适合初学数据库的人。这几个project基本上把数据库系统里一些重要话题都覆盖了,对我自己而言,这几个lab的实践确实加深了我对数据库系统当中基础概念的理解。
文章作者 bobh
上次更新 2022-05-20